I have run into situations where I just simply want to write a simple application that has Hibernate support, without having to use a full stack such as Spring Boot. It’s not hard to get going, but there are a few things to think about such as configuring Hibernate properly and managing your own transactions. The good thing is that this doesn’t take a lot of effort, as I will show you in the following tutorial.
Dependencies
To get started, here is a basic pom.xml file that will show you what dependencies you need.
dependencies {
compile 'org.hibernate:hibernate-java8:5.4.4.Final'
compile 'org.hibernate:hibernate-c3p0:5.4.4.Final'
compile 'org.jetbrains.kotlin:kotlin-stdlib-jdk8:1.3.41'
compile 'org.jetbrains.kotlin:kotlin-reflect:1.3.41'
compile 'com.h2database:h2:1.4.199'
compile 'commons-io:commons-io:2.6'
compile 'org.apache.logging.log4j:log4j-api:2.12.1'
compile 'org.apache.logging.log4j:log4j-core:2.12.1'
testCompile 'org.jetbrains.kotlin:kotlin-test:1.3.41'
}
Properties File
Next we need a properties file that will hold our Hibernate configuration
driver=org.h2.Driver
url=jdbc:h2:~/roms
user=root
pass=root
dialect=org.hibernate.dialect.H2Dialect
showSql=false
formatSql=true
currentSessionContextClass=thread
ddlAuto=validate
# Needed for a connection pool
hibernate.c3p0.min_size=1000
hibernate.c3p0.max_size=2000
hibernate.c3p0.timeout=120
hibernate.c3p0.max_statements=2000
This properties file will create an embedded H2 database. It also defines a connection pool, which is required in programs that use multiple threads, which mine often do. If you want to see the SQL that is generated, then you should flip the showSql property to true.
Entity Class
Hibernate maps objects to database tables, which means that we need an entity class.
data class AnEntity (
@Id @GeneratedValue
val id: Long? = null,
val name: String? = null
)
Boot Strapping Hibernate
At this point, we are ready to begin configuring Hibernate.
Reading the Properties File
Let’s begin by reading our properties file into memory. Here is a nice little Kotlin function that we pull a properties file from the resource folder.
fun propertiesFromResource(resource: String): Properties {
val properties = Properties()
properties.load(Any::class.java.getResourceAsStream(resource))
return properties
}
Convert Properties file to Hibernate Properties
Our next step is to read the information in the properties file and turn it into a Properties object that can be consumed by Hibernate. We can use Kotlin’s extension function feature to make this easy.
fun Properties.toHibernateProperties(): Properties {
val hibernateProperties = Properties()
hibernateProperties[Environment.DRIVER] = this["driver"]
hibernateProperties[Environment.URL] = this["url"]
hibernateProperties[Environment.USER] = this["user"]
hibernateProperties[Environment.PASS] = this["pass"]
hibernateProperties[Environment.DIALECT] = this["dialect"]
hibernateProperties[Environment.SHOW_SQL] = this["showSql"]
hibernateProperties[Environment.FORMAT_SQL] = this["formatSql"]
hibernateProperties[Environment.CURRENT_SESSION_CONTEXT_CLASS] = this["currentSessionContextClass"]
hibernateProperties[Environment.HBM2DDL_AUTO] = this["ddlAuto"]
//C3PO
hibernateProperties["hibernate.c3p0.min_size"] = this["hibernate.c3p0.min_size"]
hibernateProperties["hibernate.c3p0.max_size"] = this["hibernate.c3p0.max_size"]
hibernateProperties["hibernate.c3p0.timeout"] = this["hibernate.c3p0.timeout"]
hibernateProperties["hibernate.c3p0.max_statements"] = this["hibernate.c3p0.max_statements"]
return hibernateProperties
}
Building a Hibernate Configuration
Hibernate requires a configuration. We can use the Properties object that we made in the last step as input for creating a Hibernate configuration. Additionally, we need to supply class objects for any classes that we need Hibernate to manage. It’s best to supply this as a vararg.
fun buildHibernateConfiguration(hibernateProperties: Properties, vararg annotatedClasses: Class<*>): Configuration {
val configuration = Configuration()
configuration.properties = hibernateProperties
annotatedClasses.forEach { configuration.addAnnotatedClass(it) }
return configuration
}
Build a SessionFactory
The SessionFactory is the outcome of all of this work. It requires a Configuration in order to be created, but once you have a Configuration, it’s easy to get going in Hibernate.
fun buildSessionFactory(configuration: Configuration): SessionFactory {
val serviceRegistry = StandardServiceRegistryBuilder().applySettings(configuration.properties).build()
return configuration.buildSessionFactory(serviceRegistry)
}
Transactions
Hibernate is often used in environments where a container, such as Spring, manages your transactions automatically. In this case, we need to manually manage transactions, but Kotlin makes it really easy to eliminate the boiler plate code that would normally be required. Here is a nice little function that allows you to manage your transactions.
fun <T> SessionFactory.transaction(block: (session: Session) -> T): T {
val session = openSession()
val transaction = session.beginTransaction()
return try {
val rs = block.invoke(session)
transaction.commit()
rs
} catch (e: Exception){
logger.error("Transaction failed! Rolling back...", e)
throw e
}
}
Shutdown Hook
The final house keeping item is to make sure that we close our SessionFactory when we are finished. We can tap into the JVM’s shutdown hooks to make sure that our database connection has been closed properly.
fun addHibernateShutdownHook(sessionFactory: SessionFactory) {
Runtime.getRuntime().addShutdownHook(object: Thread() {
override fun run() {
logger.debug("Closing the sessionFactory...")
sessionFactory.close()
logger.info("sessionFactory closed successfully...")
}
})
}
Demonstration
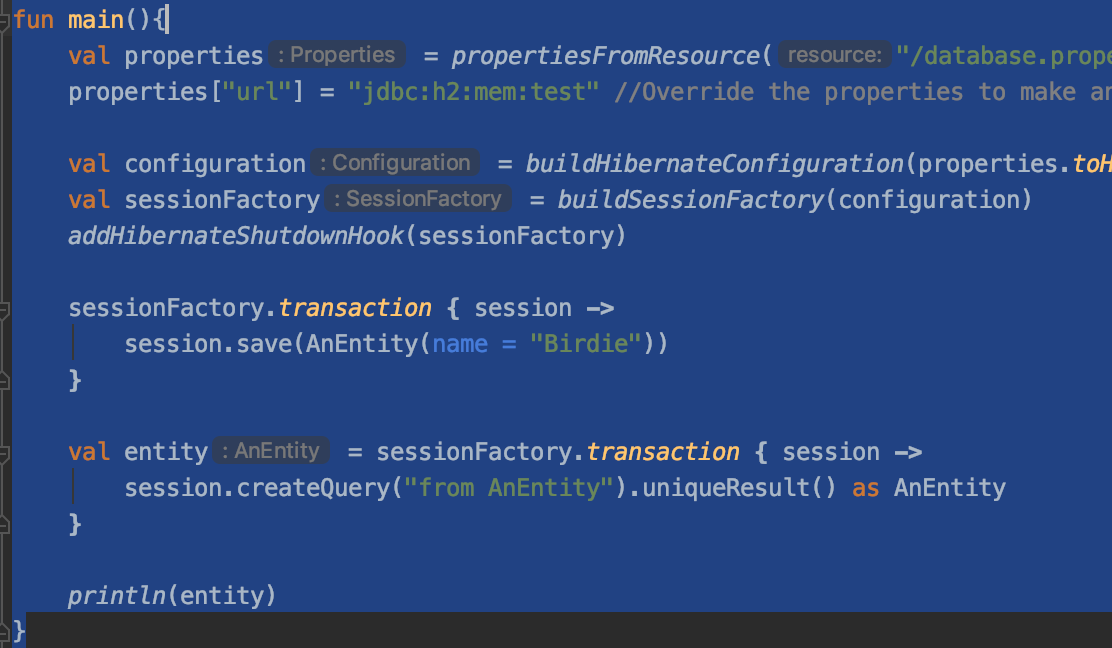
Let’s wrap this up with a nice little demonstration program that puts all of this into action!
fun main(){
val properties = propertiesFromResource("/database.properties")
properties["url"] = "jdbc:h2:mem:test" //Override the properties to make an in memory db
val configuration = buildHibernateConfiguration(properties.toHibernateProperties(), AnEntity::class.java)
val sessionFactory = buildSessionFactory(configuration)
addHibernateShutdownHook(sessionFactory)
sessionFactory.transaction { session ->
session.save(AnEntity(name = "Birdie"))
}
val entity = sessionFactory.transaction { session ->
session.createQuery("from AnEntity").uniqueResult() as AnEntity
}
println(entity)
}